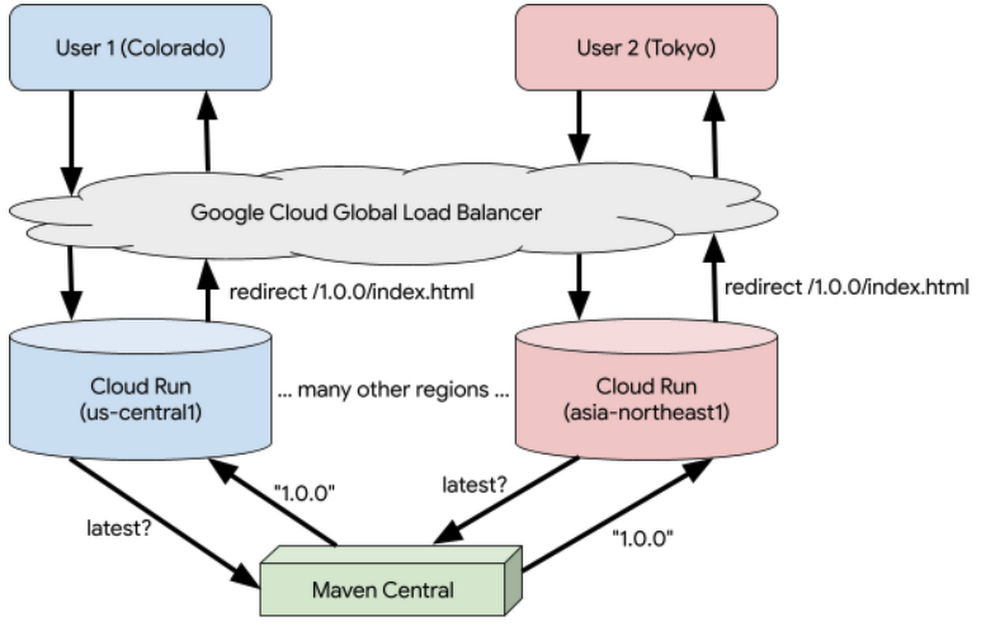
Delivering web-based software is no longer as simple as ssh’ing into a LAMP server and vi’ing a php file. For good reasons, many of us have evolved practices and adopted technologies to address growing complexities and modern needs. Recently I put together a jigsaw puzzle of various technologies and practices so that I could deploy a globally distributed, scale-on-demand, edge-cached, webapp while taking advantage of container-based portability, infrastructure automation, and Continuous Integration / Continuous Delivery.The major pieces of the puzzle include: The Java Virtual Machine (JVM), Scala, sbt, Docker, GraalVM, Cloud Native Buildpacks, bash, git, GitHub Actions, Google Cloud Run, Google Cloud Build, Google Cloud CDN, Google Container Registry, and Google Domains. That is a lot of pieces! Let’s first look at the use case that I was solving for.JavaDocs globally distributed & scale-on-demandLibraries in the JVM ecosystem (created with Java, Kotlin, Scala, etc) are typically published to a repository called Maven Central. It currently has over 6 million artifacts (a version of some library). When a library author publishes their library they typically include an artifact that contains versioned documentation (i.e. JavaDoc). These artifacts are basically ZIP files containing some generated HTML. When you use a library typically you reference its JavaDoc either in your IDE or on a webpage where it has been published.As a fun experiment I created a website that pulls JavaDocs out of Maven Central and displays them on a webpage. If you are familiar with Java libraries and can think of one, check out my website:https://javadocs.dev/As an example, check out the gRPC Kotlin stub JavaDocs:https://javadocs.dev/io.grpc/grpc-kotlin-stub/latestThat site should have loaded super fast for you, no matter where you are, because I’ve put together the puzzle of creating a scale-on-demand webapp that is globally distributed with great edge caching. Here’s what the runtime architecture looks like:1. Get latest JavaDocs for io.grpc:grpc-kotlin-stubjavadocs.dev/io.grpc/grpc-kotlin-stub/latest2. Get index.html for JavaDoc io.grpc:grpc-kotlin-stub:1.0.0javadocs.dev/io.grpc/grpc-kotlin-stub/1.0.0/index.htmlBest of all, the entire system is continuously delivered on merge to main via a few lines of Cloud Build configuration. As a spoiler, here is all the build config you need to have the same sort of globally distributed, scale-on-demand, edge-cached, webapp:To make things that easy and to make the app start super fast, I had to go on a bit of a journey putting together many different pieces. Let’s walk through everything.Super-fast startup without sacrificing developer experienceThe “JavaDoc Central” webapp is a proxy for Maven Central metadata and artifacts. It needs to query metadata from the repository like translating a version of “latest” to the actual latest version. When a user requests the JavaDoc for a given artifact it needs to pull that associated JavaDoc from Maven Central, extract it, and then serve the content.Traditionally webapp hosting relied on over-provisioning so that when a request arrives the server is ready to handle it. Scale-on-demand takes a more efficient approach where underlying resources are dynamically allocated as requests come in but are also automatically deallocated when the number of requests decreases. This is also called auto-scaling or serverless. The nice thing about scale-on-demand is that there aren’t wasted / underutilized servers. But a challenge with this approach is that applications need to startup super fast because when the demand (number of requests) exceeds the available supply (underlying servers), a new server needs to be started so the excess demand can then be handled by a freshly started server. This is called a “cold-start” and has different impacts depending on many variables: programming platform, size of application, necessity for cache hydration, connection pooling, etc.Cold-starts happen any time the demand exceeds the supply, not just when scaling up from zero servers.An easy way to deal with some cold-start issues is to use programming platforms that don’t have significant startup overhead. JVM-based applications typically take at least a few seconds to startup because the JVM has startup overhead, JAR loading takes time, classpath scanning for dependency injection can be slow, etc. For this reason technologies like Node.js, Go, and Rust have been popular with scale-on-demand approaches.Yet, I like working on the JVM for a variety of reasons including: great library & tooling ecosystem and modern high-level programming languages (Kotlin & Scala). I’m incredibly productive on the JVM and I don’t want to throw away that productivity just to better support scale-on-demand. For more details, read my blog: The Modern Java Platform – 2021 EditionLuckily there is a way to have my cake and eat it too! GraalVM Native Image takes JVM-based applications and instead of running them on the JVM, it Ahead-Of-Time (AOT) compiles them into native applications. But that process takes time (minutes, not seconds) and I wouldn’t want to wait for that to happen as part of my development cycle. The good news is that I can run JVM-based applications on the JVM as well as native images. This is exactly what I do with the JavaDoc Central code. Here is what my development workflow looks like:To create a native image with GraalVM I used a build tool plugin. Since I’m using Scala and the sbt build tool, I used the sbt-native-packager plugin but there are similar plugins for Maven and Gradle. This enables my Continuous Delivery system to run a command to create an AOT native executable from my JVM-based application:./sbt graalvm-native-image:packageBinGraalVM Native Image optionally allows native images to be statically linked so they don’t even need an operating system to run. The resulting container image for my entire statically linked JavaDoc webapp is only 15MB and starts up in well under a second. Perfect for on-demand scaling!Multi-region deployment automationWhen I first deployed the javadocs.dev site I manually created a service on Cloud Run that runs my 15MB container image but Cloud Run services are region-based so latency to them differ depending on where the user is (turns out the speed of light is fairly slow for round-the-globe TCP traffic). Cloud Run is available in all 24 Google Cloud regions but I didn’t want to manually create all those services and the related networking infrastructure to handle routing. There is a great Cloud Run doc called “Serving traffic from multiple regions” that walks through all the steps to create a Google Cloud Load Balancer in front of n-number of Cloud Run services. Yet, I wanted to automate all that so I embarked on a journey that further complicated my puzzle but resulted in a nice tool that I use to automate global deployments, network configurations, and global load balancing.There are a number of different ways to automate infrastructure setup, including Terraform support for Google Cloud. But I just wanted a container image that’d run some gcloud commands for me. Writing those commands is pretty straightforward but I also wanted to containerize them so they’d be easily reusable in automated deployments.Typically, to containerize stuff like this, a Dockerfile is used to define the steps needed to go from source to the thing that will be runnable in the container. But Dockerfiles are only reusable with copy & paste resulting in security and maintenance costs that are not evident initially. So I decided to build a Cloud Native Buildpack for gcloud scripts that anyone could reuse to create containers for gcloud automations. Buildpacks provide a way to reuse the logic for how source gets turned into runnable stuff in a container.After an hour of learning how to create a Buildpack, the gcloud-buildpack was ready! There are only a couple pieces which you don’t really need to know about since Buildpacks abstracts away the process of turning source into a container image, but let’s go into them so you can understand what is under-the-covers.Buildpack run imageBuildpacks add docker layers onto a “run image” so a Buildpack needs one of those. My gcloud-buildpack needs a run image that has the gcloud command in it. So I just created a new run image based on the gcloud base image and with two necessary labels (Docker metadata) for the Buildpacks:I also needed to setup automation so the run image would automatically be created and stored on a container registry, and any changes would update the container image. I decided to use GitHub Actions to run the build and the GitHub Container Registry to store the container image. Here is the Action’s YAML:Voila! The run image is available and continuously deployed:ghcr.io/jamesward/gcloud-buildpack-run:latestgcloud BuildpackBuildpacks participate in the Cloud Native Buildpack lifecycle and must implement at least two phases: detect & build. Buildpacks can be combined together so you can run something like:pack build –builder gcr.io/buildpacks/builder:v1 fooAnd all of the Buildpacks in the Builder Image will be asked if they know how to build the specified thing. In the case of the Google Cloud Buildpacks they know how to build Java, Go, Node.js, Python, and .NET applications. For my gcloud Buildpack I don’t have plans to add it to a Builder Image so I decided to have my detection always result in a positive result (meaning the buildpack will run no matter what). To do that my detect script just exits without an error. Note: You can create Buildpacks with any technology since they run inside the Builder Image in docker; I just decided to write mine in Bash because reasons.The next phase for my gcloud Buildpack is to “build” the source but since the Buildpack is just taking shell scripts and adding them to my run image, all that needs to happen is to copy the scripts to the right place and tell the Buildpack lifecycle that they are executables / launchable processes. Check out the build code.Since Buildpacks can be used via container images, my gcloud Buildpack needs to be built and published to a container registry. Again I used GitHub Actions:From the user’s perspective, to use the gcloud Buildpack all they have to do is:Create a project containing a .sh fileBuild your project with pack:Now with a gcloud Buildpack in place I’m ready to create a container image that makes it easy to deploy a globally load-balanced service on Cloud Run!Easy Cloud RunI created a bash script that automates the documented steps to setup a multiregion Cloud Run app so that they can all be done as part of a CI/CD pipeline. If you’re interested, check out the source. Using the new gcloud-buildpack I was able to package the command into a container image via GitHub Actions:Now anyone can use the ghcr.io/jamesward/easycloudrun container image with six environment variables, to automate the global load balancer setup and multi-region deployment. When this runs for the javadoccentral repo it looks like this:All of the networking and load balancer configuration is automatically created (if it doesn’t exist) and the Cloud Run services are deployed with the –ingress=internal-and-cloud-load-balancing option so that only the load balancer can talk to them. Even the http to https redirect is created on the load balancer. Here is what the load balancer and network endpoint groups look like in the Google Cloud Console:Setting up a serverless, globally distributed application that is backed by 24 Google Cloud regions all happens in about 1 minute as part of my CI/CD pipeline.Cloud Build CI/CDLet’s bring this all together into a pipeline that tests the javadocs.dev application, creates the GraalVM Native Image container, and does the multi-region deployment. I used Cloud Build since it has GitHub integration and uses service accounts to control the permissions of the build (making it easy to enable Cloud Run deployment, network config setup, etc). The Cloud Build definition (source on GitHub):Step 1 runs the application’s tests. Step 2 builds the application using GraalVM Native Image. Step 3 pushes the container images to the Google Cloud Container Registry. And finally Step 4 does the load balancer / network setup and deploys the application to all 24 regions. Note that I use a large machine for the build since GraalVM Native Image uses a lot of resources. The only custom value in that CI/CD pipeline is the DOMAINS which are needed to setup the load balancer. Everything else is boilerplate.The puzzle comes together!So that was quite the jigsaw puzzle with many pieces! Now that I’ve glued all the pieces together it should be pretty straightforward for you to create your own serverless, globally distributed application on Google Cloud and deploy with easycloudrun. Or maybe you want to use the gcloud Buildpack to create your own automations. Either way, let me know how I can help!Related ArticleIntroducing Cloud Run Button: Click-to-deploy your git repos to Google CloudAdding the Cloud Run button to your github source code repositories lets anyone deploy their application to Google Cloud.Read Article
Quelle: Google Cloud Platform
Published by