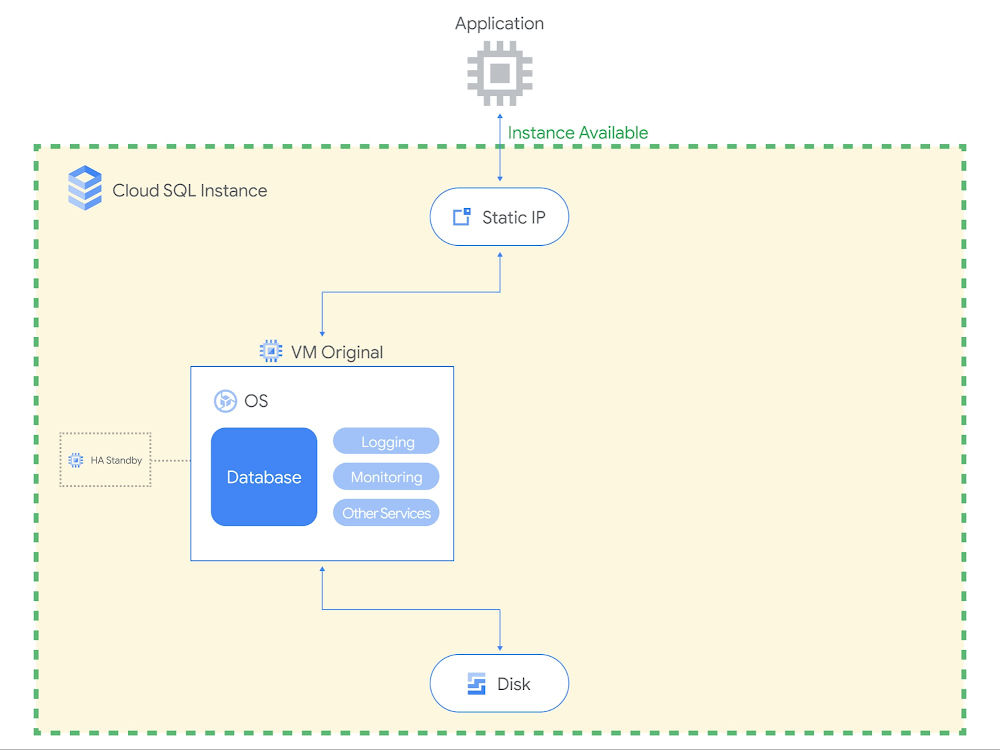
Imagine never needing to patch your database ever again. If you’ve had to previously take down your production database to update its operating system, you know patching can be quite the chore. Cloud SQL users happily cross this burden off their to-do list, since Cloud SQL manages routine database maintenance for them. But what all is included in maintenance, and how long does maintenance take to complete?In Part 1 of this blog series, I introduced how maintenance fits together with other Cloud SQL system updates to keep users’ instances running optimally. In Part 2 of this series, I’ll be going into more detail about what changes are included in Cloud SQL maintenance, how long it lasts, and how we’ve designed maintenance to minimize application downtime.What changes are made during Cloud SQL maintenance?Maintenance events are software rollouts that update a Cloud SQL instance’s operating system and the database engine. Cloud SQL performs maintenance to ensure that our users’ databases are reliable, secure, performant, and up-to-date with the latest features. Through maintenance, we deliver new Cloud SQL features, database version upgrades, and operating system patches.Cloud SQL features.In order to launch new features like IAM database authentication and database auditing, we update the database engine and install new plugins to the database.Database version upgrades. The database software providers that develop MySQL, PostgreSQL, and SQL Server deploy new releases several times a year. With each new minor version comes bug fixes, security patches, performance enhancements, and new database features. Users can check these out by reviewing the MySQL, PostgreSQL, and SQL Server release notes. We upgrade Cloud SQL instances to the most recent minor version shortly after release, so that our users benefit from running the latest database engine.Operating system patches. We continuously monitor for newly identified security vulnerabilities in the VM operating system. Upon discovery, we patch the operating system to protect customers from new exploitsThese updates require us to disconnect the database instance temporarily. While maintenance is crucial for ensuring applications run smoothly, we understand that nobody likes service disruption. We typically bundle these improvements together and schedule maintenance once every few months.How long is the database down during maintenance?As of August 2021, the typical period of connectivity loss for a database instance is:PostgreSQL – 30 seconds or lessMySQL – 60 seconds or lessSQL Server – 120 seconds or lessIf you’ve been self-managing databases and performing maintenance using rolling updates across a cluster, you may be used to even faster numbers than what is available today in database-as-a-service. We are always working to bring Cloud SQL maintenance downtime closer towards zero, and this year we completed a redesign of our maintenance workflow to significantly reduce maintenance downtime. Maintenance downtime is on average 80% shorter than it was 12 months ago. For MySQL and PostgreSQL, Cloud SQL’s average maintenance downtime is now shorter than that of Amazon RDS and Azure Database, according to figures published in online documentation as of August 2021.What happens during maintenance downtime?To understand why maintenance incurs downtime, you need to understand Cloud SQL’s maintenance workflow. Cloud SQL utilizes a shared disk failover workflow for maintenance that largely resembles our automatic failover workflow for highly available instances. In short, we set up an updated database with the new software, stop the original database, start up the updated database, and then switch over the disk and static IP to the updated database.Let’s do a walkthrough with some visuals. In the pre-maintenance state (see below diagram), the client communicates to the original VM through a static IP address. The data is stored on a persistent disk that is attached to the original VM. In this example, the Cloud SQL instance has high availability configured, which means that another VM is on standby to take over in the event of an unplanned outage. The Cloud SQL instance is serving traffic to the application.Before maintenanceIn Step 1, as shown below, we set up an updated VM with the latest database engine and OS software. The updated VM gets fully up and running, apart from the database engine which hasn’t yet started. For highly available instances, we also set up a new standby VM as well. Note that the updated VM is set up in the same zone as the original VM, so that the Cloud SQL instance will communicate to the application from the same zone after maintenance as it did before maintenance. By installing the software update on another VM while the Cloud SQL instance is still serving traffic to the application, we substantially shorten the total downtime.Step 1: Set up updated VMIn Step 2, we gracefully shut down the database engine on the original VM. The database engine needs to be shut down so that the disk can be detached from the original VM and attached to the updated VM. Before shutting down, the database engine waits for a few seconds for ongoing transactions to be committed and existing connections to drain out. After that, any open transactions or long-running transactions are rolled back. During this process, the database stops accepting new connections and existing connections are dropped. Step 2 is when the instance first becomes unavailable and maintenance downtime begins.Step 2: Shut down original VM (downtime begins)In Step 3, the disk is detached from the original VM and attached to the updated VM. The static IP address is reconfigured to point to the updated VM as well. This ensures that the IP address the application used before maintenance remains the same after maintenance too. Note that the database cache is cycled out with the original VM, meaning that the database cache is effectively cleared during maintenance.Step 3: Switch over to updated VMIn Step 4, the updated database engine is started up on the now-attached disk. Using a single disk ensures that all transactions written to the instance prior to maintenance are still present on the updated instance after maintenance. In the event that any incomplete transactions didn’t finish rolling back during database engine shutdown, the database engine automatically goes through crash recovery in order to ensure that the database is restored to a usable state. Note that crash recovery means that downtime is higher for instances experiencing high activity when maintenance begins.Step 4: Start up updated VM (downtime ends on completion)Upon the completion of Step 4, the Cloud SQL instance is once again available to accept connections and back to serving traffic to the application.After maintenanceTo the application, apart from the updated software, the Cloud SQL instance looks the same. The application still connects to the Cloud SQL instance using the same static IP address, and the updated VM is running in the same zone as the original VM. All data written to the original database is preserved.Hopefully, these diagrams explain why maintenance still incurs some downtime, even after our improvements. We still invest in making maintenance even faster. To stay current with our latest maintenance downtime numbers, check out our documentation.What are Cloud SQL users doing to reduce impact from maintenance even further? Stay tuned for Part 3, where we will cover how users optimize for maintenance by utilizing Cloud SQL maintenance settings and designing their applications to be resilient to maintenance.Related ArticleUnderstanding Cloud SQL Maintenance: why is it needed?Get acquainted with the way maintenance works in Cloud SQL so you can effectively plan availability.Read Article
Quelle: Google Cloud Platform
Published by